近年来,大语言模型(LLMs)展现出强大的语言理解与生成能力,推动了文本生成、代码生成、问答、翻译等任务的突破。代表性模型如 GPT、Claude、Gemini、DeepSeek、Qwen 等,已经深刻改变了人机交互方式。LLMs 的边界也不止于语言和简单问答。随着多模态(VLMs)与推理能力(LRMs)的兴起,LLMs 正不断扩展到多模态理解、生成与复杂推理场景。
但模型性能持续提升的背后,是模型尺寸、数据规模、RL 推理长度的快速 Scaling,是算力和存储资源的急剧消耗。大模型的训练与推理的成本居高不下,成为制约其广泛落地和应用的现实瓶颈。
本文从 LLM 架构角度出发,带你剖析大模型的效率秘诀。这一切的核心在于 Transformer 架构。Transformer 的自注意力机制虽带来了远距离建模的突破,却因 O(N2) 的复杂度在长序列任务中成本高昂。而在 RAG、智能体、长链推理、多模态等新兴场景下,长序列需求愈发突出,进一步放大了效率与性能之间的矛盾。同时 Transformer 的 FFN 部分采用密集的 MLP 层,同样面临模型规模放大后的训练和推理效率问题。
作者:机器之心
链接:https://zhuanlan.zhihu.com/p/1943373121248822632
论文标题:Speed Always Wins: A Survey on Efficient Architectures for Large Language Models论文地址:https://arxiv.org/pdf/2508.09834
项目仓库:https://github.com/weigao266/Aw
图 2:大语言模型高效架构概览
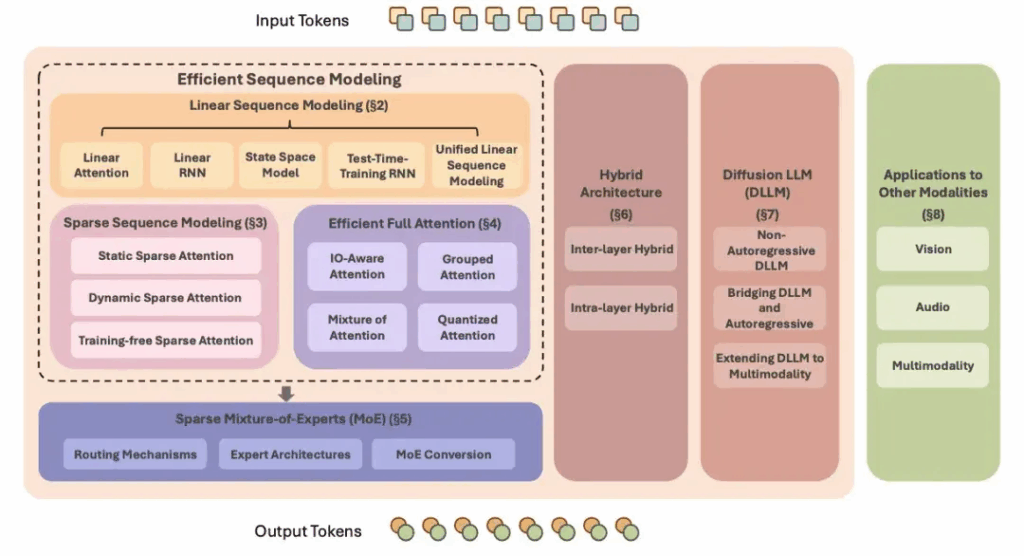
该综述将目前 LLM 高效架构总结分类为以下 7 类:
- 线性序列建模:降低注意力训练和推理复杂度,无需 KV Cache 开销。
- 稀疏序列建模:通过稀疏化注意力矩阵,降低计算与显存需求。
- 高效全注意力:在保持完整注意力的前提下优化内存访问与 KV 存储。
- 稀疏专家模型:通过条件激活部分专家,大幅提升模型容量而不增加等比例计算成本。
- 混合模型架构:结合线性/稀疏序列建模与全注意力,兼顾效率与性能。
- 扩散语言模型:利用非自回归的扩散模型进行语言生成。
- 其他模态应用:将这些高效架构应用于视觉、语音、多模态模型。
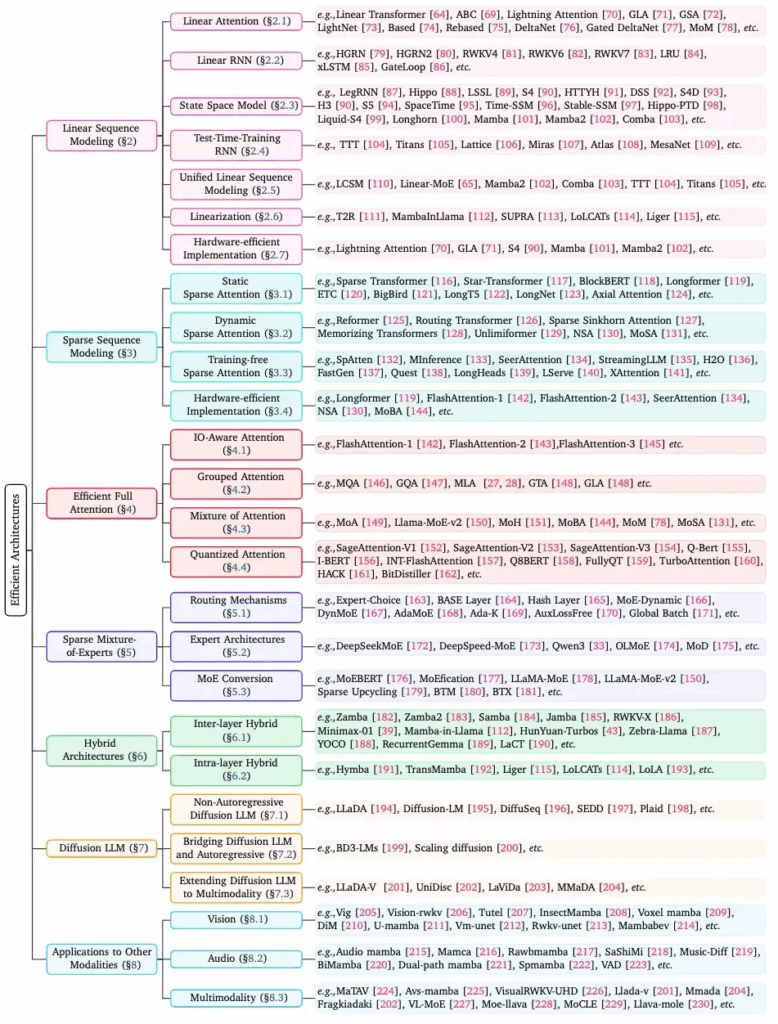
图 3:综述完整组织架构
作者:机器之心
链接:https://zhuanlan.zhihu.com/p/1943373121248822632
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
线性序列建模
线性序列建模是近年来研究相当火热的一个方向,代表性工作像 Mamba、Lighting Attention、RWKV、GLA、TTT 等在模型架构方向都引起过广泛关注。我们将这类技术细分为以下几个类别:
- 线性注意力
- 线性 RNN
- 状态空间模型
- 测试时推理 RNN
并且正如在多篇文献里已经提出的,这些线性序列建模方法可以概括为统一建模的数学形式,并且能够通过线性化过程将预训练模型权重的 Softmax Attention 架构转为 Linear Sequence Modeling 架构,从而获得模型效率的大幅提升,如下图所示。
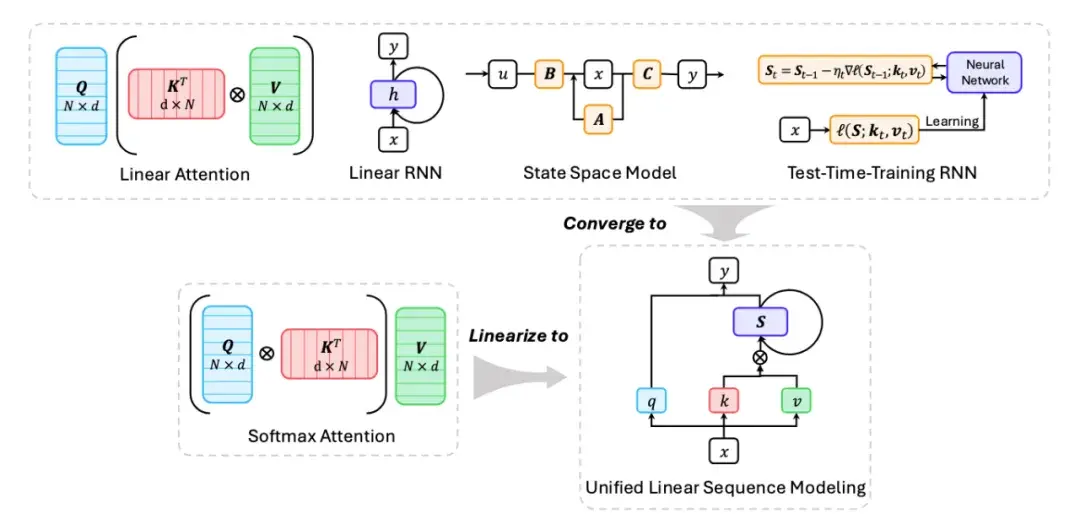
图 4:线性序列建模方法
我们将已有的线性序列建模方法从记忆视角和优化器视角分别进行梳理和对比,详细形式可见下表:
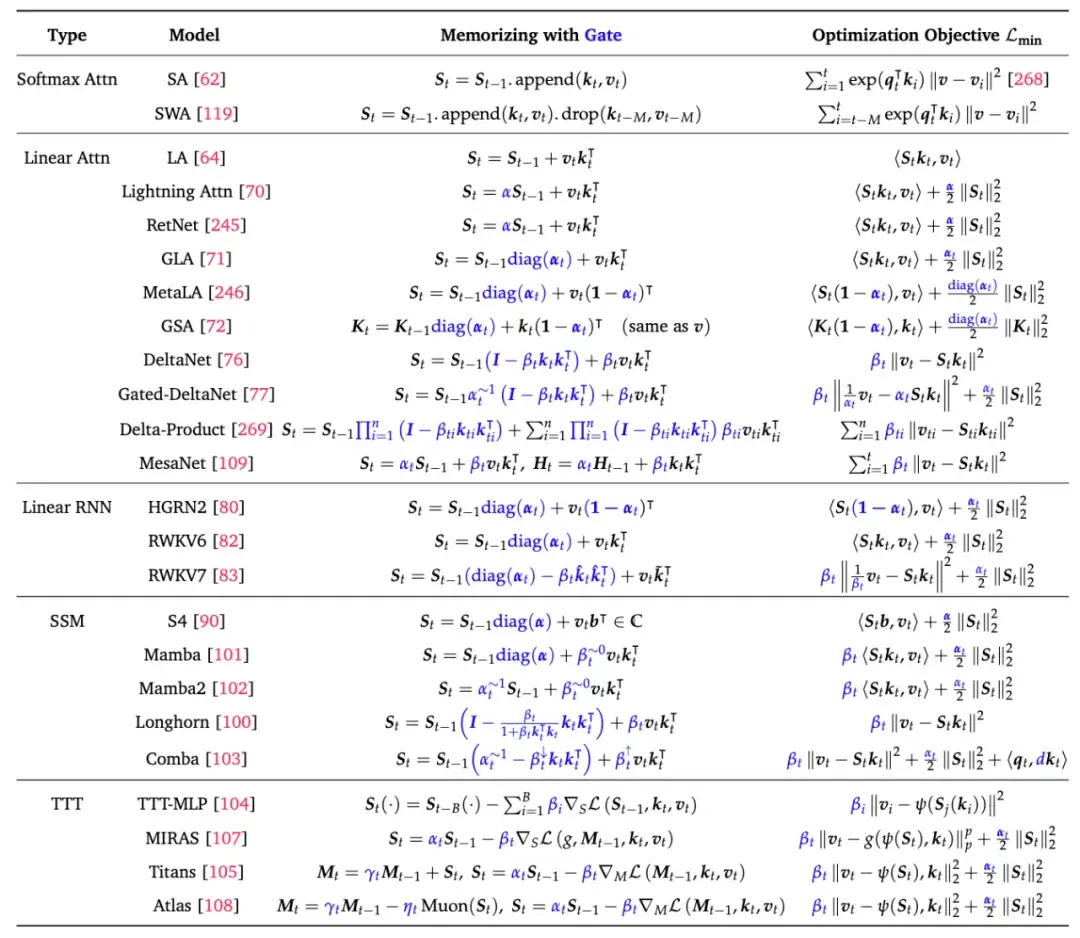
表 1:线性序列建模方法统一建模的 Memory 视角和 Optimizer 视角
其中线性化技术可以进一步细分为基于微调的线性化,和基于蒸馏的线性化,如下图所示:
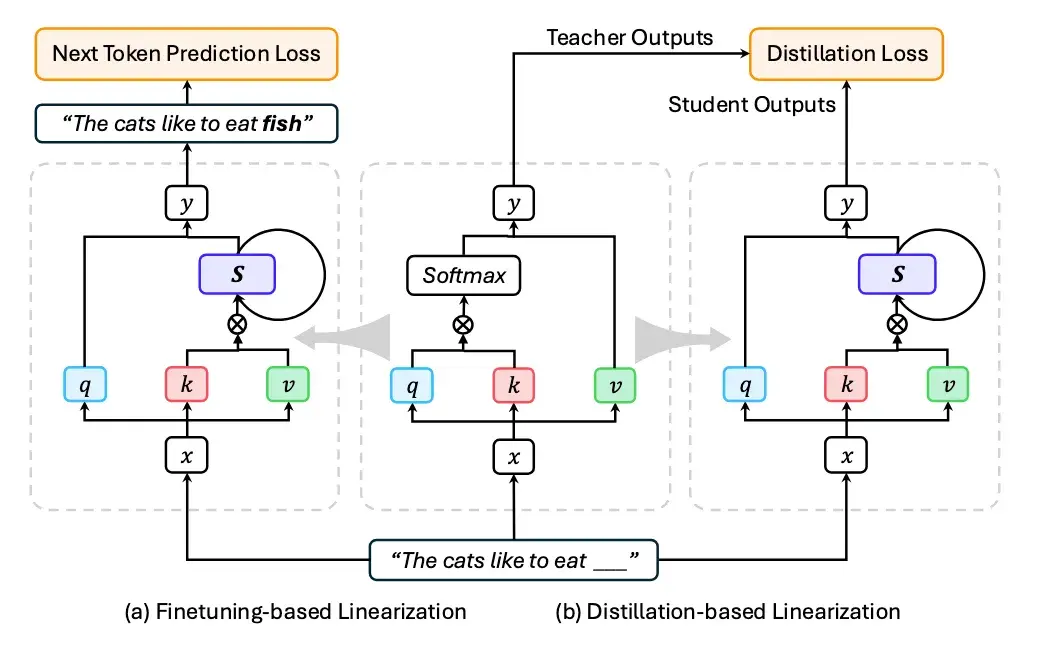
图 5:线性化方法
综述还进一步总结归纳了目前在线性序列建模领域常见的硬件高效实现方法,可以归纳为 Blelloch Scan、Chunk-wise Parallel 和 Recurrent for Inferences,如下图所示:
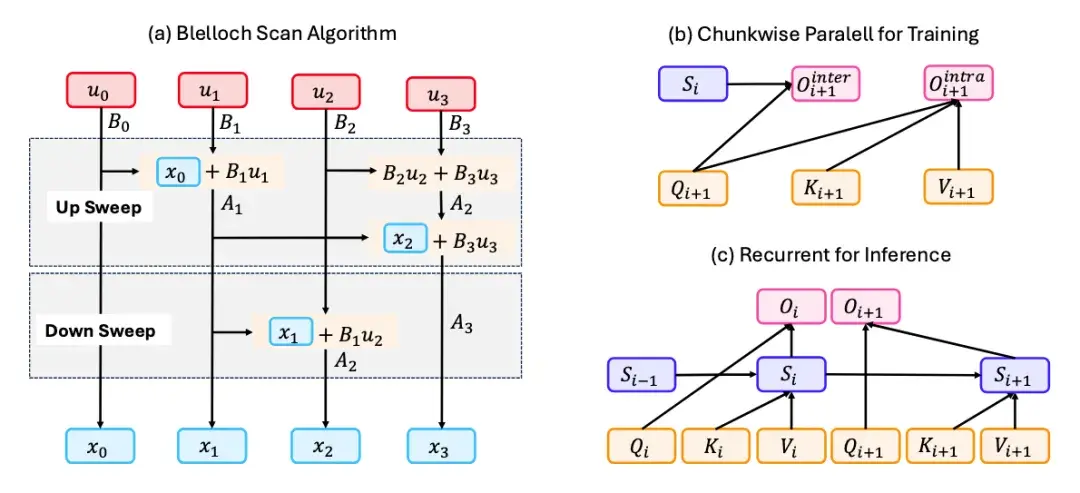
图 6:线性序列建模方法的硬件高效实现
稀疏序列建模
稀疏序列建模是另一类有代表性的高效注意力机制,通过利用 Attention Map 天然具有的稀疏性加速注意力的计算,这类方法可以进一步细分为:
- 静态稀疏注意力
- 动态稀疏注意力
- 免训练稀疏注意力
代表性的稀疏注意力方法如 Global Attention、Window Attention、Dilated Attention 等,及其工作原理如下图所示:
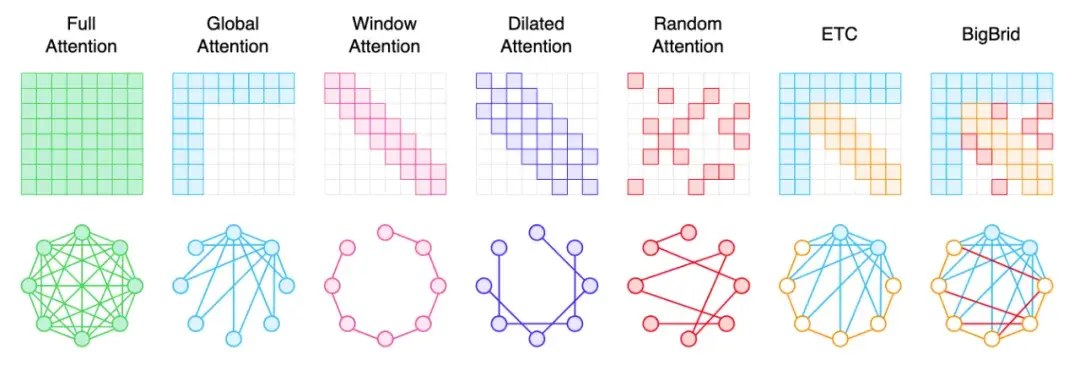
图 7:稀疏注意力的几种经典形式
高效全注意力
另一类高效注意力算法可以统一归纳为高效全注意力,这类方法可以根据算法思路进一步细分为如下几类:
- IO-Aware Attention
- Grouped Attention
- Mixture of Attention
- Quantized Attention
其中 IO-Aware Attention 指代目前使用非常广泛的 Flash Attention 系列工作,Grouped Attention 则包含广为使用的 GQA、MLA 等全注意力变体,几种代表性方法如下图所示。
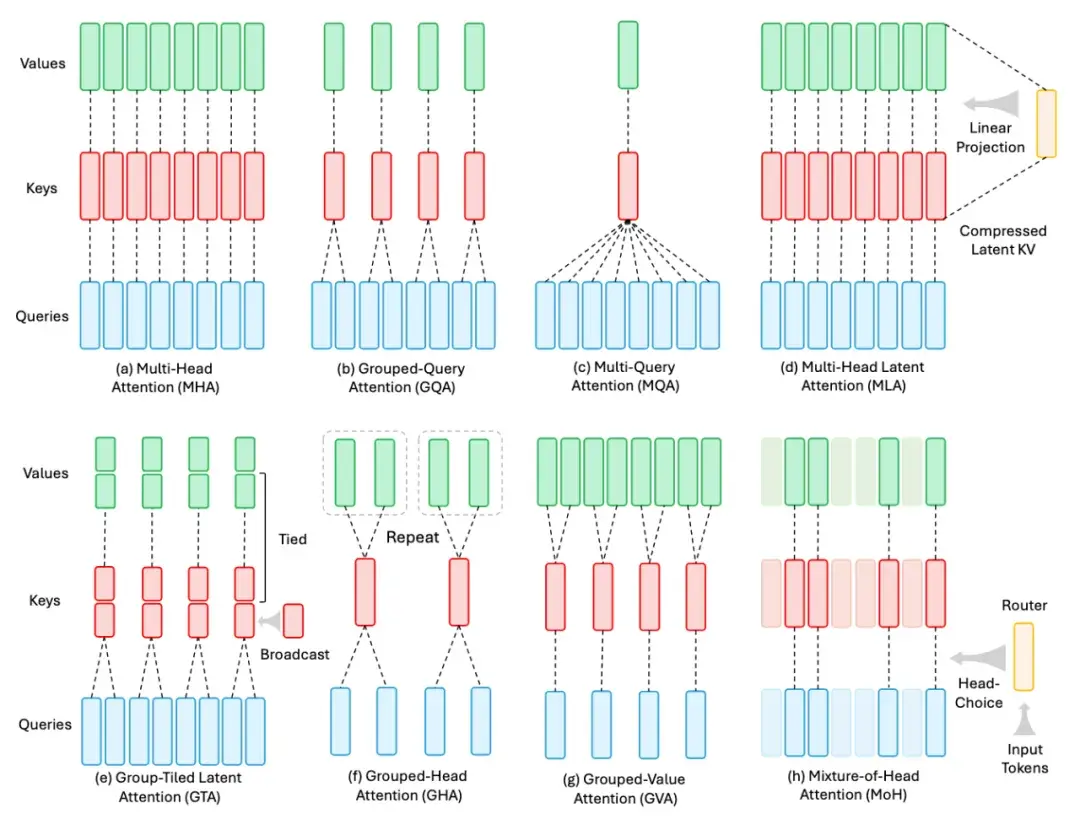
图 8:Grouped Attention 的几种代表性方法
稀疏混合专家
稀疏混合专家是对 Transformer 架构中另一个重要模块 FFN 做的一类重要改进,已经逐渐成为(语言和多模态)大模型架构的事实标准。综述中将相关文献按以下三个方向进行分类:
- Routing Mechanisms
- Expert Architectures
- MoE Conversion
路由机制包括 Token-choice 和 Expert-choice 两类,其原理如下图所示:
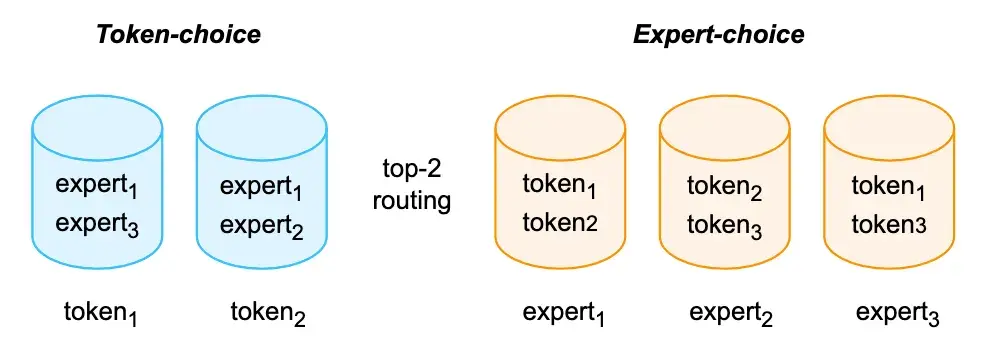
图 9:MoE 路由机制
专家结构的创新工作包括:共享专家、细粒度专家、零专家、深度路由等,其作用和原理可见下图:
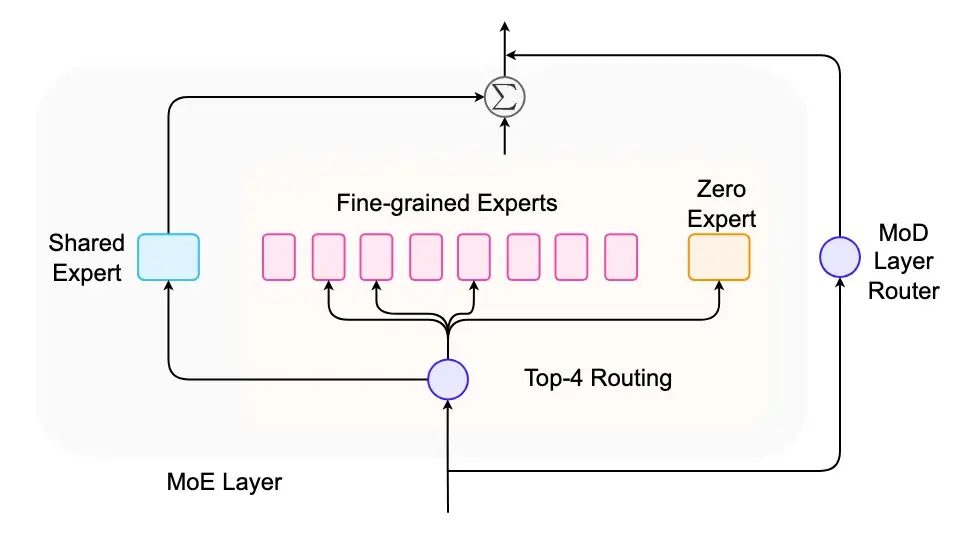
图 10:MoE 专家架构
另外一个重要的方向是 MoE 转换,已有的工作包括通过 Split、Copy、Merge 等手段对专家进行构造,如下图所示:
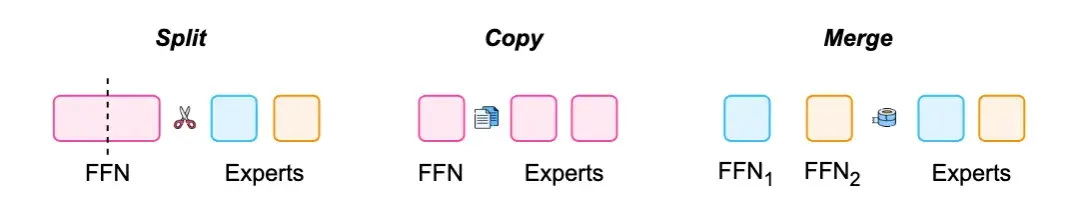
图 11:MoE 转化机制
混合架构
混合架构是近年来出现的一种实用的新型架构,可以在线性/稀疏注意力和全注意力之间取得微妙的 Trade-off,也在效率和效果间找到了最佳甜蜜点。具体可细分为:
- 层间混合
- 层内混合
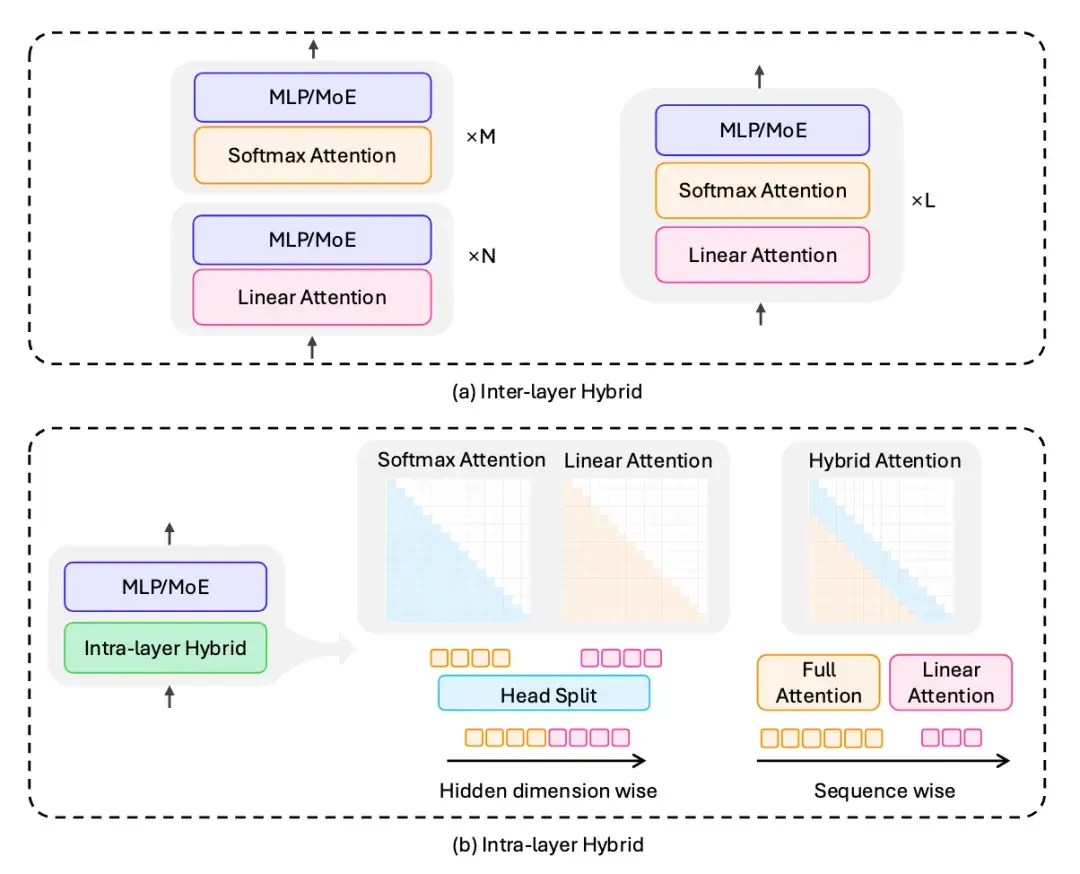
图 12:混合架构形式
扩散大语言模型
扩散大语言模型是近期出现的一个热门方向,创新性地将扩散模型从视觉生成任务迁移至语言任务,从而在语言生成速度上取得大幅进步。相关工作可以细分为:
- Non-Autoregressive Diffusion LLM
- Bridging Diffusion LLM and Autoregressive
- Extending Diffusion LLM to Multimodality
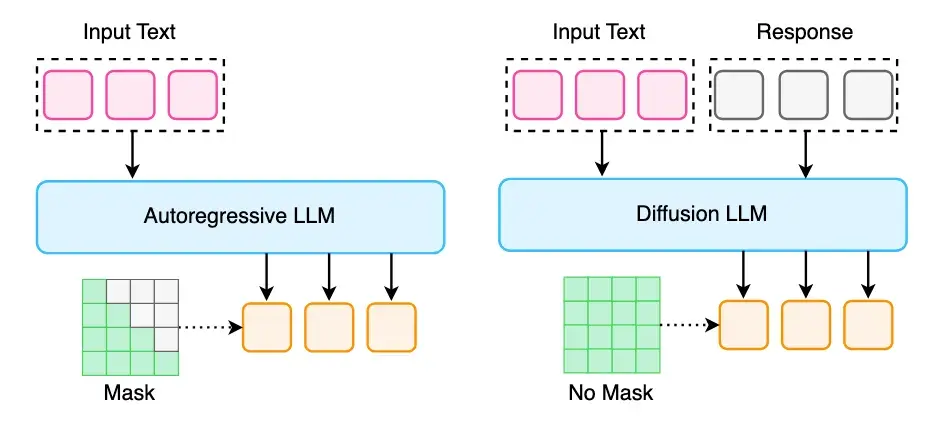
图 13:扩散大语言模型机制
应用至其他模态
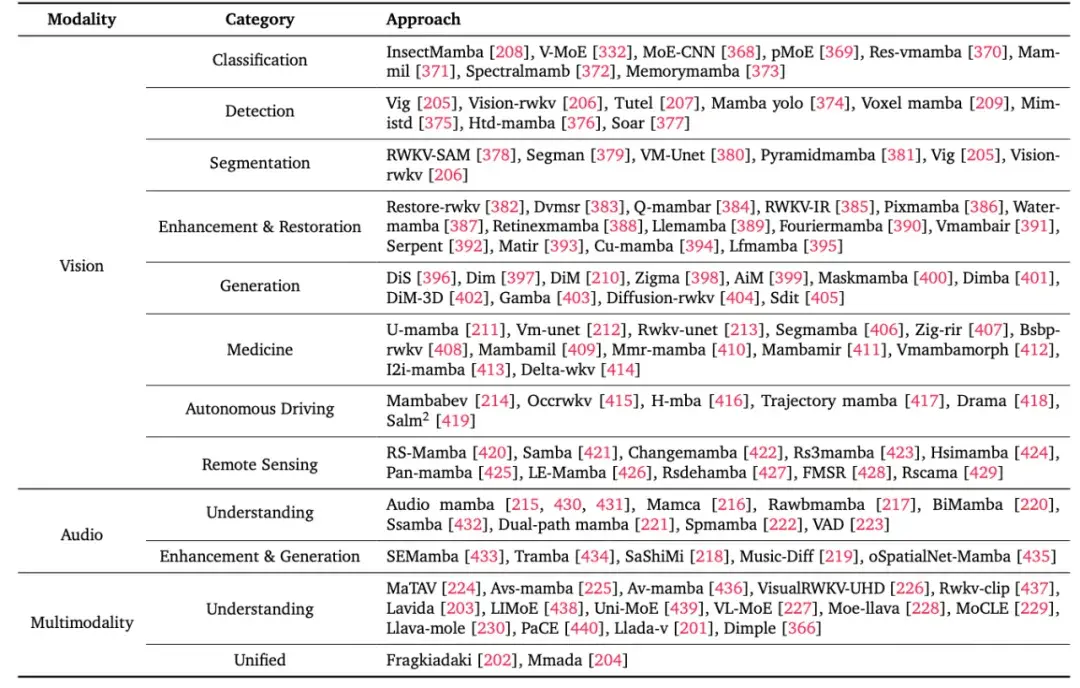
最后一个重要的部分是高效架构在其他模态上的应用,涵盖视觉、音频和多模态。以 Mamba 为代表的线性模型被广泛应用至多种模态任务上,并取得了优秀的表现,综述将这类模型总结梳理至如下表格:
回复 song 取消回复