LongCat团队 美团技术团队2025年12月8日 10:24北京
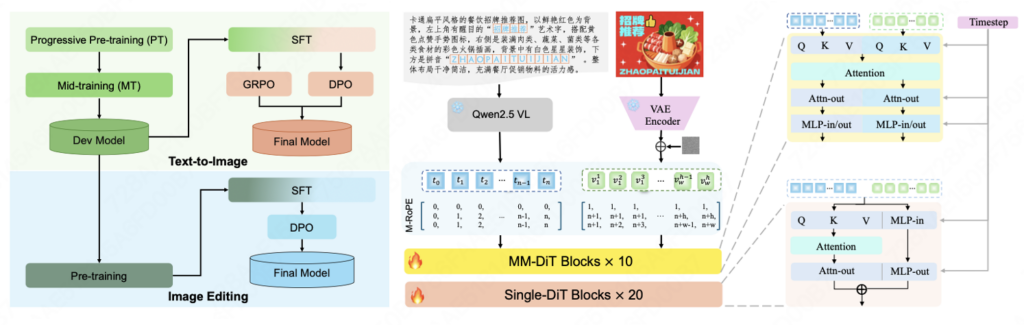
当前 AI 图像生成技术需求旺盛,但行业陷入 “两难困境”:闭源大模型性能强劲但无法自行部署或二次定制开发,开源方案普遍存在轻量化与模型性能难以兼顾、面向商用专项能力不足的痛点,制约商业创作与技术普惠。为此,美团 LongCat 团队正式发布并开源 LongCat-Image 模型,通过高性能模型架构设计、系统性的训练策略和数据工程,以6B参数规模,成功在文生图和图像编辑的核心能力维度上逼近更大尺寸模型效果,为开发者社区与产业界提供了 “高性能、低门槛、全开放” 的全新选择。
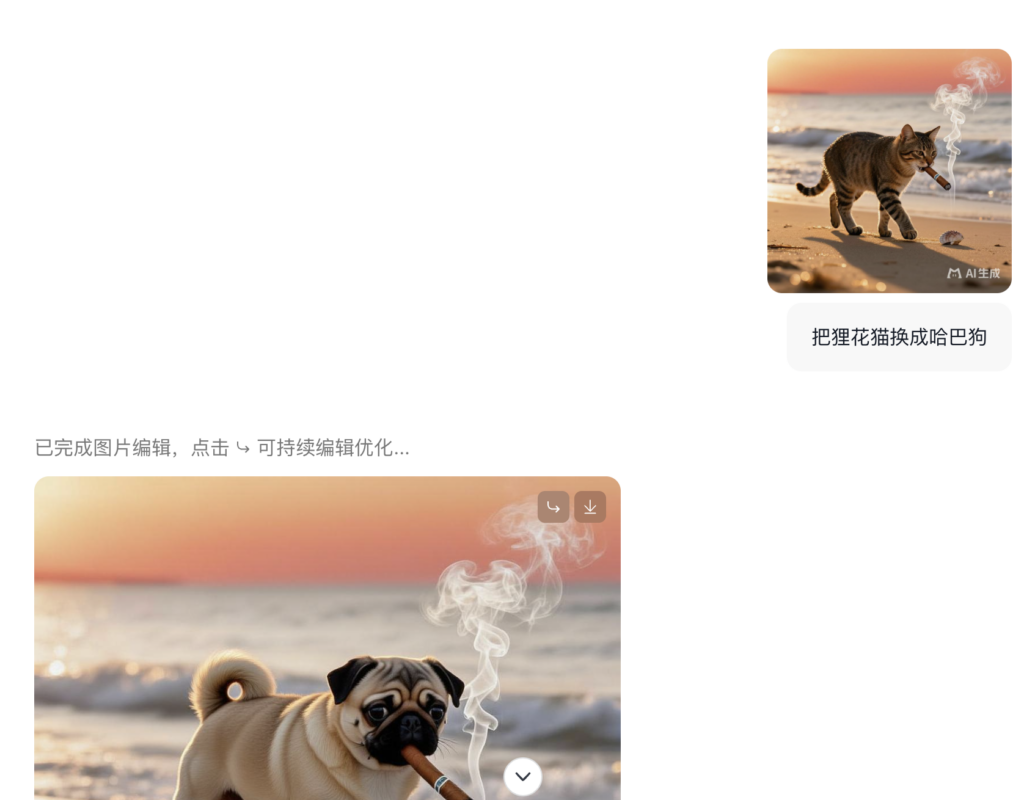
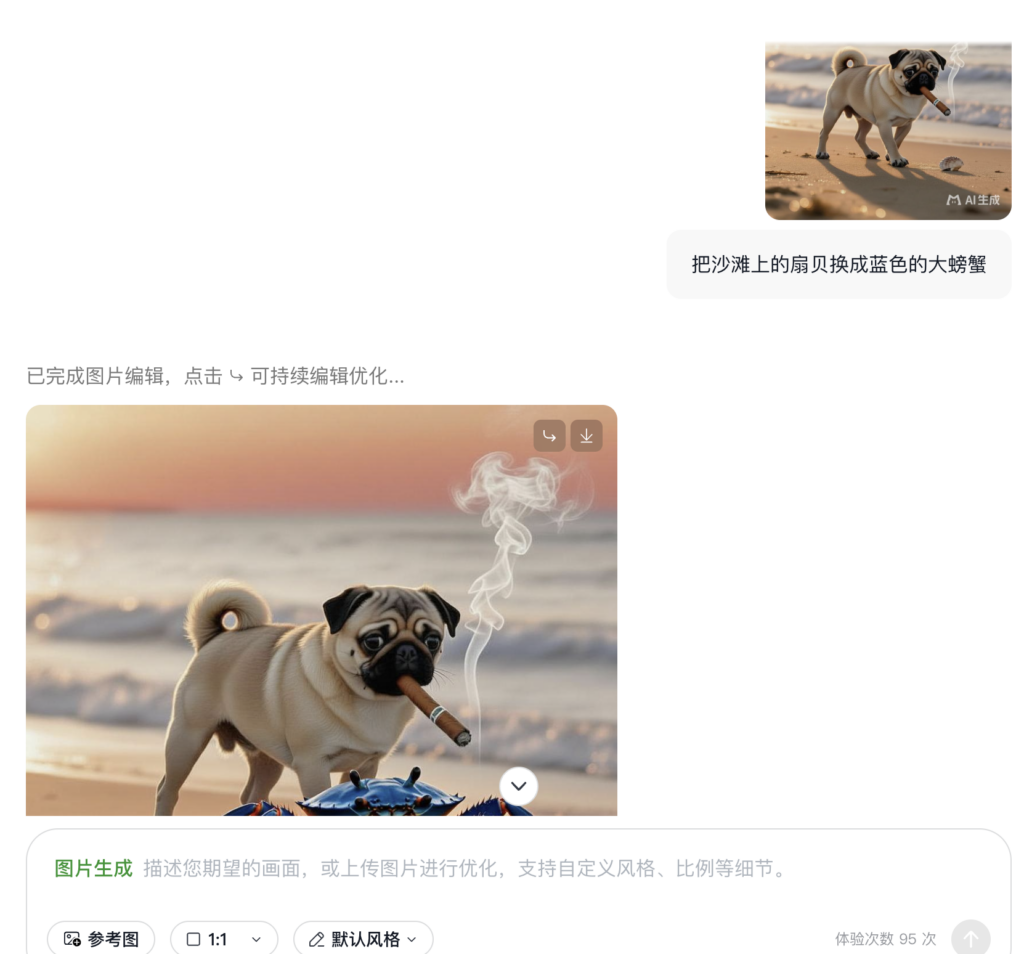
亮点一:图像编辑高度可控
LongCat-Image 在图像编辑领域的多个重要基准测试中(如GEdit-Bench、ImgEdit-Bench)均达到开源SOTA水平,实现性能突破的背后在于一套紧密协同的训练范式和数据策略。
亮点二:中文文字生成精准覆盖
针对中文文本渲染这一行业痛点,LongCat-Image 通过课程学习策略来提升字符覆盖度和渲染精准度:预训练阶段基于千万量级合成数据学习字形,覆盖通用规范汉字表的8105个汉字;SFT 阶段引入真实世界文本图像数据,提升在字体、排版布局上的泛化能力;RL 阶段融入 OCR 与美学双奖励模型,进一步提升文本准确性与背景融合自然度。此外通过对 prompt 中指定渲染的文本采用字符级编码,大幅降低模型记忆负担,实现文字生成学习效率的跨越式提升。通过该项能力加持,有效支持海报设计、商业广告作图场景中复杂笔画结构汉字的渲染,以及古诗词插图、对联、门店招牌、文字Logo等设计场景的生僻字渲染。
此外,LongCat-Image通过系统性的数据筛选与对抗训练框架,实现了出图纹理细节和真实感的提升。预训练和中期训练阶段严格过滤AIGC数据,避免陷入“塑料感”纹理的局部最优;在SFT阶段,所有数据均经过人工精筛来对齐大众审美;在RL阶段,创新性地引入AIGC内容检测器作为奖励模型,利用其对抗信号逆向引导模型学习真实世界的物理纹理、光影和质感。
发表回复