https://www.arxiv.org/pdf/2505.09343
深度解析 DeepSeek-V3:扩展挑战与硬件架构反思
1. 背景与目标
DeepSeek-V3 是由 DeepSeek-AI 开发的超大规模语言模型,基于其前代 DeepSeek-V2 的架构进行了多方面的优化。论文的主要目标是:
- 分析大规模 LLM 在训练和推理中面临的硬件瓶颈。
- 探讨模型与硬件协同设计(co-design)的必要性。
- 提出面向未来的AI 硬件架构建议,以支持更高效的 LLM 扩展。
论文主要聚焦于其系统级架构设计、通信机制优化、网络拓扑结构改进,以及这些因素如何影响模型的性能和成本效率。
2. DeepSeek-V3 的核心架构设计
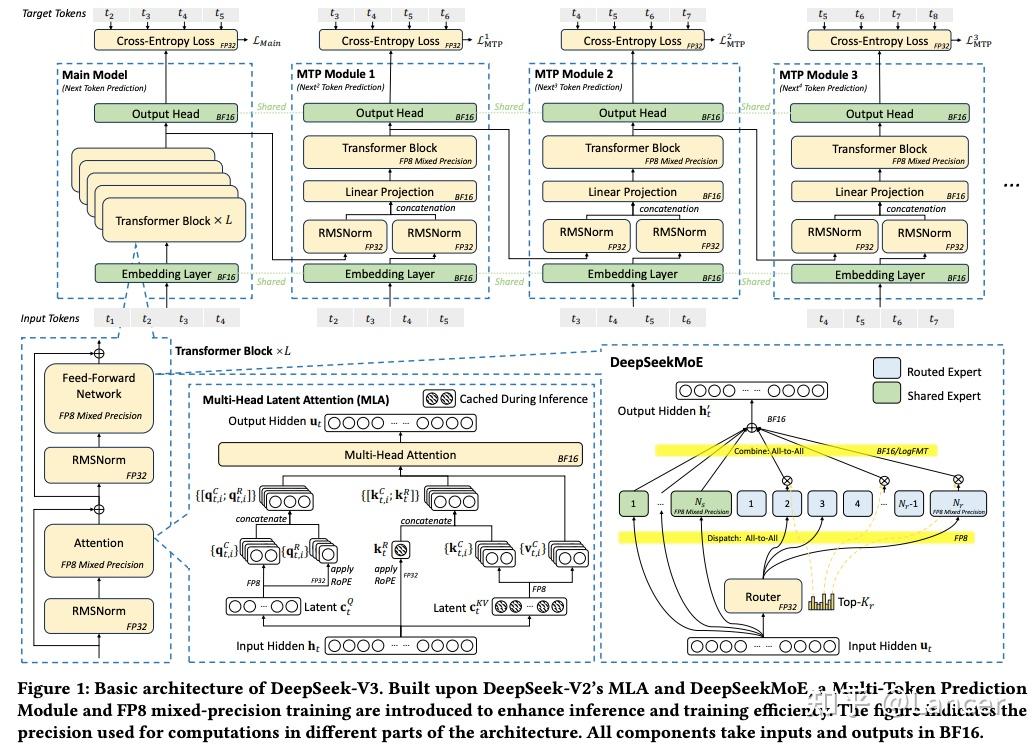
2.1 多头潜在注意力机制(Multi-head Latent Attention, MLA)
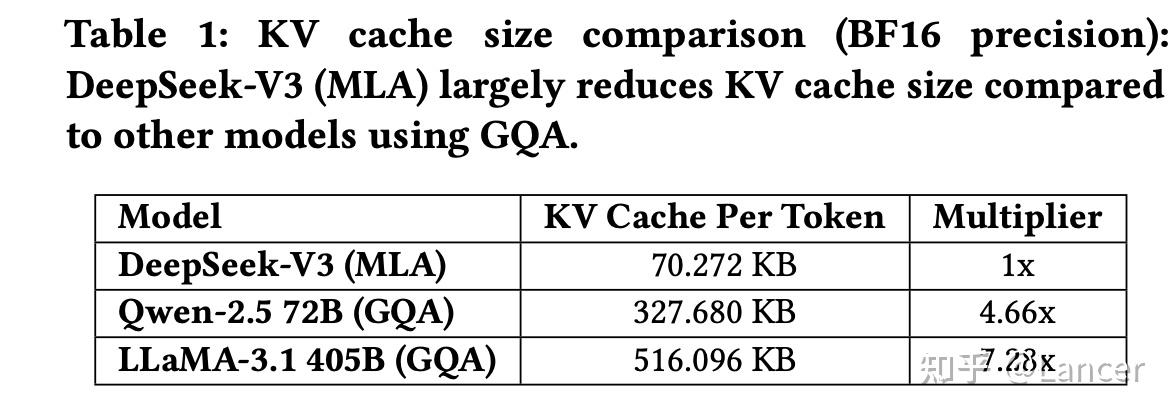
MLA 是一种旨在提升内存效率的注意力机制。传统的 Transformer 注意力机制需要存储大量的 Key/Value 缓存(KV Cache),这在处理长序列时会造成显著的内存负担。MLA 引入了“潜在表示”(latent representation),通过压缩 KV 缓存来减少内存占用。
2.2 混合专家架构(Mixture of Experts, MoE)优化
MoE 是 DeepSeek-V3 的核心技术之一,它通过稀疏激活机制,在不增加计算资源的前提下显著提升模型参数规模。
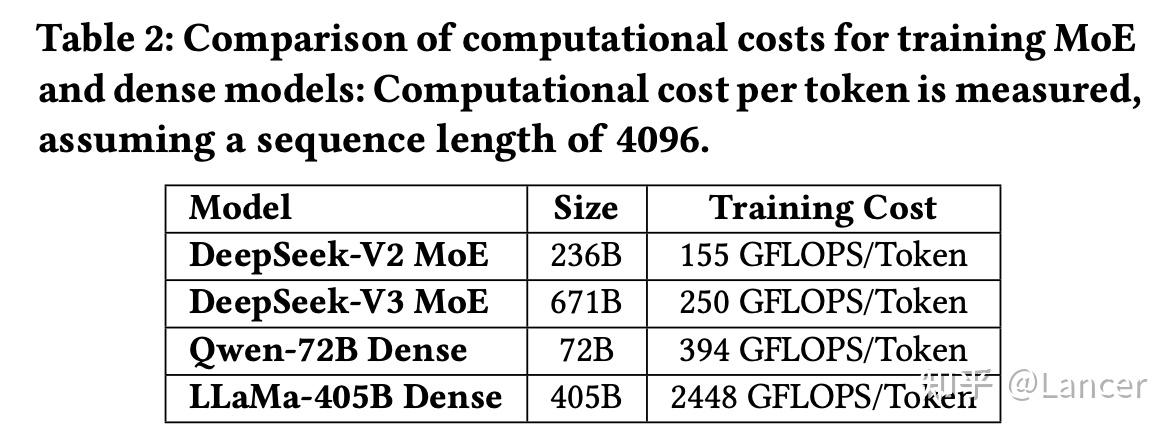
- 参数规模大但计算成本低:例如,DeepSeek-V3 总参数达到 671B,但每个 token 只激活约 37B 参数。
- 灵活的路由策略:采用 Top-K 路由算法选择最相关的专家模块。
- 分布式训练优化:结合 All-to-All 通信模式,实现高效的专家并行(Expert Parallelism, EP)。
实现难点:
- 通信开销大:EP 需要频繁的 All-to-All 数据交换。
- 负载不均衡:某些专家可能被频繁调用,造成热点问题。
为解决这些问题,DeepSeek 团队开发了 DeepEP,一个高效的 EP 实现库,并开源供社区使用。
2.3 多令牌预测模块(Multi-Token Prediction Module, MTP)
MTP 是为了加速推理而设计的模块,允许模型在同一时间步预测多个 token,从而显著提高吞吐量。
工作原理:
- 在解码阶段,同时生成多个候选 token。
- 利用 speculative sampling 策略,提前预测后续 token。
- 结合硬件加速器(如 GPU 的 Tensor Core)提升并行处理能力。
效果:
- 显著减少推理延迟。
- 在消费级 GPU 上也可实现高吞吐(如运行 DeepSeek-V3 的 TPS 达到 ~20)。
3. 低精度计算与通信优化
随着 LLM 的参数规模不断增长,传统高精度浮点运算(如 FP32 或 BF16)在计算资源、内存带宽和能耗方面带来了巨大压力。尤其是在 MoE 架构中,专家模块之间的频繁通信进一步加剧了对带宽的需求。
MoE 中有两个关键阶段涉及大量通信:
- Dispatch 阶段
- 输入 token 被路由到多个专家模块。
- 使用 FP8 或 LogFMT 压缩后,传输数据量减少,通信时间显著缩短。
- Combine 阶段
- 来自多个专家的输出被聚合。
- 如果在此阶段也使用压缩通信,可以避免带宽瓶颈,提升聚合效率。
DeepSeek 团队提出了 FP8 混合精度训练 和 LogFMT 通信压缩格式 等创新技术,构建了一个以低精度为核心的系统级优化框架,从而在不牺牲模型性能的前提下,显著提升了训练和推理效率。
3.1 FP8 混合精度训练
DeepSeek-V3 采用了 FP8 混合精度训练技术,以降低计算和通信带宽需求。
实现方式:
- 在关键计算路径(如注意力矩阵计算、FFN 层)使用 FP8。
- 其他部分保留更高精度(如 BF16)以保持数值稳定性。
- 动态调整精度策略,根据层或操作类型切换精度。
优点:
- 减少内存占用和数据传输带宽。
- 加快训练速度,尤其在带宽受限的集群环境中。
尽管 FP8 混合精度训练带来了显著收益,但仍存在一些限制:
- 累加精度不足 Hopper GPU 的 Tensor Core 在执行 FP8 GEMM 时仅维护 13 位尾数(FP22),并截断超出部分。这可能导致:
- 长序列注意力计算中的误差累积。
- 权重更新不稳定,影响收敛速度。
- 数值稳定性问题 FP8 的动态范围有限,尤其在某些极端输入场景下可能出现溢出或下溢,影响模型稳定性。
- 软件支持不完善 目前主流框架(如 PyTorch)对 FP8 的支持仍处于早期阶段,需大量自定义代码实现:
- 自定义量化/反量化函数。
- 自定义 GEMM 内核(如 DeepGEMM 开源项目)。
- 混合精度调度逻辑复杂。
未来方向:
- 为 FP8 或自定义精度格式提供原生压缩/解压单元 ,是解决当前 AI 通信瓶颈的重要方向。
- 它能显著降低通信带宽需求 ,并提升通信效率 ,尤其适用于 MoE 这类通信密集型任务。
- 未来硬件应考虑将这些功能集成到网络接口控制器(NIC)、I/O die 或 GPU 内部逻辑中 ,以实现真正的高效通信
3.2 LogFMT通讯压缩
LogFMT 是 DeepSeek-V3 提出的一种基于对数空间的新型量化格式,在一定程度上是为了弥补 FP8 的不足而提出的 。其核心思想是将数值从线性空间转换到对数空间,从而使得数据分布更均匀,便于进行低比特量化。
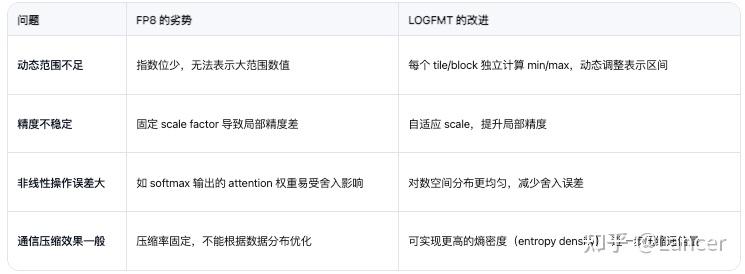
数据结构定义(LogFMT-nBit):
- 第一位为符号位 S。
- 剩余 n-1 位编码 log(|xi|) 的值。
每个 tile 独立计算 min/max,并据此归一化其他值,实现自适应量化范围。
主要可以应用在以下几个阶段:
- MoE 的 Dispatch 阶段 :令牌被路由前进行低精度编码。
- KV Cache 压缩 :缓存 Key/Value 向量,减少内存占用。
- 中间结果通信 :Transformer 层之间传递激活值时使用。
存在的局限:
- 当前 GPU 不支持 LogFMT 原生运算,需软件层实现,带来额外延迟。
- 编解码过程较复杂,增加了计算负担。
- 目前主要用于通信压缩,在关键计算路径(如注意力矩阵、FFN 层)仍需使用 FP8/BF16。
未来方向:
- 硬件原生支持 :建议未来 GPU 和网络芯片支持 LogFMT 编解码功能。
- 混合精度策略 :结合 LogFMT 与 FP8/BF16,在不同阶段灵活切换。
- 自动 rounding 到线性空间 :确保量化过程无偏,避免在对数空间直接舍入造成的误差。
4. 互联网络优化与 Scale-up/Scale-out 架构融合
DeepSeek-V3 基于 NVIDIA H800 GPU 构建,并采用高性能互连技术(如 InfiniBand 和 NVLink)进行节点间通信;
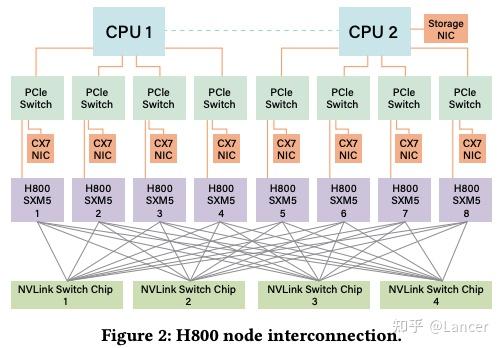
网络拓扑:
- 每个 H800 节点配备 8 个 400Gbps InfiniBand (IB) NIC 。
- 实现了接近 50GB/s 的有效带宽 (考虑小数据包和延迟影响后实际约为 40GB/s)。
- 相比之下,NVLink 提供约 160GB/s 的带宽 (单向)。
为满足监管要求,FP64 性能和 NVLink 带宽被削减。
- NVLink 带宽从 900 GB/s 降至 400 GB/s,导致节点内通信能力下降
为此, 每个节点配备 8 个 400Gbps InfiniBand NIC,增强节点间通信能力,同时DeepSeek-V3 通过软件优化(如 Node-Limited Routing、LogFMT 等)弥补硬件限制,实现高效训练。
4.1 Hardware-Aware Parallelism(硬件感知并行)
DeepSeek 团队提出了 Hardware-Aware Parallelism 策略,旨在根据硬件特性优化模型并行方式,以提升整体训练和推理效率。
| 并行类型 | 是否使用 | 使用场景 | 说明 |
| Tensor Parallelism (TP) | 否(训练时) 是(推理时) | 推理加速 | 避免在训练中使用,因 NVLink 带宽限制导致低效;推理时选择性使用以降低延迟。 |
| Pipeline Parallelism (PP) | 是 | 训练加速 | 使用 DualPipe 技术重叠 attention 与 MoE 计算,减少 pipeline bubbles。 |
| Expert Parallelism (EP) | 是 | MoE 分布式处理 | 使用 DeepEP 实现高效的 All-to-All 通信,开源实现。 |
4.2 模型架构与硬件协同设计: Node-Limited Routing
在 DeepSeek-V3 所使用的 NVIDIA H800 GPU 架构 中,存在明显的 Scale-Up(节点内)与 Scale-Out(节点间)通信带宽不匹配问题 :
| 通信类型 | 带宽理论值 | 实际有效带宽 | 带宽比例(近似) |
| Scale-Up (NVLink) | 200 GB/s | ~160 GB/s | 4:1 |
| Scale-Out (IB NIC) | 50 GB/s | ~40 GB/s (由于小数据包传输和延迟影响) | – |
为了解决这些问题,DeepSeek 团队提出了 Node-Limited Routing(节点限制路由) 和 TopK 专家选择策略 ,通过将专家部署在有限数量的节点上,从而减少跨节点通信量。
- 专家分组与部署
- 将总共 256 个专家 分成 8 组 。
- 每组包含 32 个专家 ,并部署在 同一个节点 上。
- Token 路由策略
- 每个 token 最多被路由到 4 个节点 。
- 这样可以确保:
- 跨节点通信量减少。
- 同一节点内的专家可通过高速 NVLink 通信,降低延迟。
假设使用 8 个节点 (共 64 个 GPU),每个 GPU 有 4 个专家,总共有 256 个专家,每个 token 被路由到 1 个共享专家 + 8 个目标专家。
- 传统实现:
- 如果这 8 个目标专家分布在所有 8 个节点上,则需进行 8 次 IB 通信。
- 总通信时间为
8 * t(t 为单次 IB 传输时间)。
- Node-Limited Routing 方法
- 目标专家被限制在最多 4 个节点。
- 每个节点只需一次 IB 传输,然后通过 NVLink 在节点内广播。
- 总通信时间降至
4 * t,节省了 50% 的通信开销。
4.3 Scale-up 与 Scale-out 网络融合
当前硬件中,Scale-up(节点内)和 Scale-out(节点间)网络是分离的,导致通信路径复杂、延迟高。
尽管 MPFT 和 EP 等技术取得了良好效果,但仍面临一些挑战:
- 当前 IB ConnectX-7 不支持多平面无缝通信,需通过节点转发,增加延迟。
- 软件复杂度高 :
- Node-Limited Routing 策略增加了通信流水线 kernel 的实现复杂度。
- GPU Streaming Multiprocessors(SM) 需要同时处理网络消息填充和 NVLink 转发,消耗计算资源。
- 内存一致性问题 :
- 使用 load/store 语义进行跨节点通信时,需显式插入内存屏障(fence),影响吞吐。
- RDMA 中也存在 out-of-order synchronization 问题。
未来方向:
- 统一网络适配器(Unified Network Adapter)、
- 设计支持统一 Scale-Up 与 Scale-Out 网络的 NIC 或 I/O Die。
- 支持基本交换功能,如将 Scale-Out 数据包转发到特定 GPU。
- 使用单一 LID/IP 地址 + 策略路由,简化地址管理。
- 专用通信协处理器(Dedicated Communication Co-Processor)
- 引入专用协处理器或可编程组件(如 I/O Die),处理网络流量。
- 卸载 GPU SM 上的通信任务,防止性能退化。
- 支持硬件加速的内存拷贝、广播、转发操作。
- 灵活的数据转发、广播与归约机制
- 硬件应支持灵活的转发机制,用于 MoE 分发和聚合。
- 支持高效的归约操作(reduce),提升通信效率。
- 实现类似于当前 GPU SM-based 实现的机制,但由硬件直接完成。、
- 低延迟互连与同步原语
- 支持 acquire/release 同步语义,减少软件同步开销。
- 提供硬件级原子操作、屏障指令,提升通信效率。
- 支持乱序包到达的硬件排序(RAR 机制)。
实现 Scale-Up 与 Scale-Out 网络融合之后,AI 系统将获得以下显著优势:
| 优势 | 描述 |
| 更低的通信延迟 | 统一网络接口减少了中间转发步骤,提升通信效率。 |
| 更高的有效带宽利用率 | 可动态分配带宽资源,适应不同工作负载需求。 |
| 更简单的软件栈 | 无需区分 intra-node 与 inter-node 通信,简化调度逻辑。 |
| 更强的可扩展性 | 更容易支持超大规模集群(如 10k+ GPU)。 |
| 更好的负载均衡能力 | 可根据网络状态动态选择最优路径,避免热点瓶颈。 |
4.4 带宽争用与延迟
在 H800 GPU 架构中,GPU 和 CPU 之间的 PCIe 接口是连接主存和显存的关键路径。然而,在大规模训练或推理过程中,多个任务会同时争夺有限的 PCIe 带宽,导致性能下降。
比如在以下两种场景下:
- KV Cache 传输 :
- 在推理阶段,需要频繁将 Key/Value cache从 CPU 内存拷贝到 GPU 显存。
- 这类操作可能占用数十 GB/s 的带宽。
- 专家并行(EP)通信 :
- MoE 模型中的 All-to-All 通信也依赖 IB NIC 和 GPU 之间的数据交换。
- 如果 EP 通信和 KV Cache 传输同时进行,PCIe 带宽就会成为瓶颈。
因此,会导致存在以下问题:
- 性能下降 :带宽争用会导致整体吞吐下降。
- 延迟增加 :某些任务的完成时间被显著延长。
- 资源利用率低 :GPU 可能因等待数据而处于空闲状态
优化建议:
- 动态优先级调度机制,根据不同类型的流量需求,动态调整带宽分配策略。保证关键任务(如推理任务)的低延迟执行。防止非关键任务占用过多带宽,提升整体效率。
- 对不同类型流量设定不同优先级,例如:
- 高优先级:EP、TP、KV Cache 传输
- 中低优先级:其他后台任务
- 在 PCIe 上暴露 Traffic Class (TC) 给用户空间程序,实现灵活控制。
- 对不同类型流量设定不同优先级,例如:
- 将网卡直接集成到 I/O Die 中(Chiplet架构),减少 PCIe 成为瓶颈的风险,提升整体系统的可扩展性和稳定性,并降低通信延迟
- 将 InfiniBand 或 RoCE 网卡直接集成到封装级别的 I/O Die 中。
- 通过封装内互连技术(如 NVLink、Infinity Fabric)连接 GPU Compute Die。、
- 使用 NVLink 替代 PCIe,统一 Scale-Up 域内的 CPU-GPU 通信 ,通过优化节点内部 CPU 与 GPU 的通信效率,避免 PCIe 成为瓶颈
- 使用 NVLink、Infinity Fabric 等高速互连技术替代传统 PCIe。
- 将 CPU 和 GPU 放入同一个 Scale-Up 域中。
5 大规模网络驱动设计
随着 LLM(大型语言模型)参数规模的指数级增长,传统的三层 Fat-Tree(FT3)拓扑在成本、可扩展性和鲁棒性方面逐渐暴露出局限性。特别是在 MoE 架构下,All-to-All 通信密集型操作对带宽提出了更高要求。
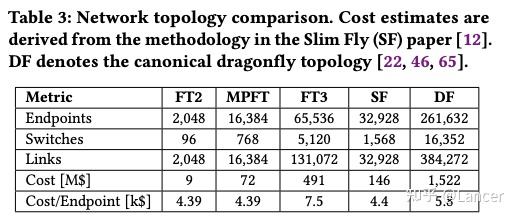
5.1 Multi-Plane Fat-Tree 网络拓扑(MPFT)
DeepSeek-V3 部署了一个基于 InfiniBand 的多平面两层 Fat-Tree 网络(MPFT),用于替代传统的三层 Fat-Tree 架构,如图Figure 3所示。
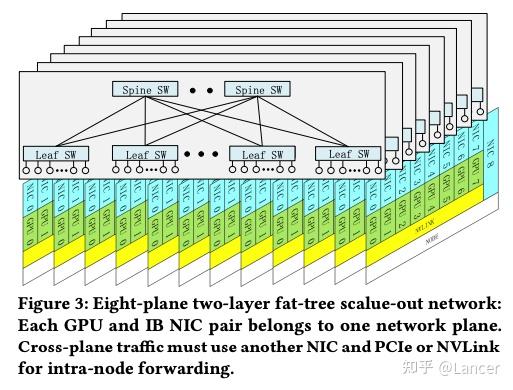
架构特点:
- 每个节点配备 8 块 GPU 和 8 个 400Gbps InfiniBand NIC 。
- 每块 GPU 对应一个独立的 IB NIC,属于不同的“网络平面”(plane)。
- 所有节点连接到 64-port 400G IB 交换机 ,构成两层 Fat-Tree。
- 此外,每个节点还配置了一个 RoCE NIC,用于连接分布式文件系统(如 3FS),实现存储网络隔离。
优点:
- 成本更低:相比三层 Fat-Tree,MPFT 可节省高达 40% 的网络成本。
- 更高的可扩展性:理论上支持最多 16,384 个 GPU。
- 流量隔离:每个平面独立运行,避免跨平面拥塞。
尽管 MPFT 在理论上具有强大的优势,理想情况如Figure 4所示,
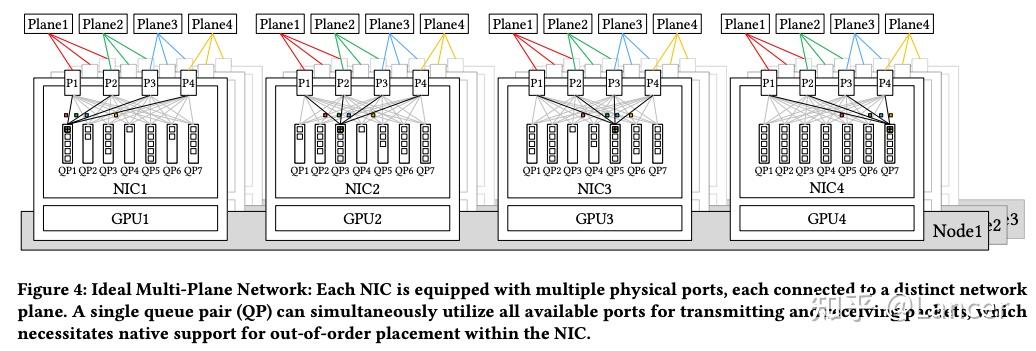
但实际上受限于IB ConnectX-7硬件,主要表现在:
- 不支持真正的多平面通信。
- QP 数据包无法自动在多个平面上负载均衡。
- 若需要跨平面通信,必须通过节点内转发(intra-node forwarding),引入额外延迟。
但是NVIDIA 新一代网卡 ConnectX-8 已原生支持 4 个网络平面(4-plane),可以在一个 QP 上实现真正的 multi-path packet spraying。并支持硬件级乱序包处理,确保数据一致性。
5.2 低延迟网络
DeepSeek-V3 的训练依赖于超大规模集群(如 2048 块 H800 GPU),而 MoE(Mixture of Experts)架构下的专家并行(EP)操作对带宽和延迟都非常敏感。因此,网络延迟的优化对于提升整体系统性能至关重要。
1. InfiniBand vs. RoCE:性能对比
在 DeepSeek-V3 的部署中,使用了 InfiniBand(IB)作为主要通信协议。为了评估其性能优势,论文对比了 IB 与 RoCE 在不同场景下的端到端延迟表现。
64B 数据传输延迟对比:
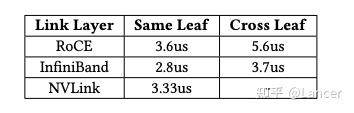
可以发现:
- InfiniBand 延迟最低,是当前最适合 MoE 架构下 All-to-All 通信的网络协议。
- RoCE 虽具成本优势,但延迟较高,尤其在跨 Leaf 交换机时表现不佳。
- NVLink 提供了最低的节点内通信延迟,适用于 Tensor Parallelism 和 KV Cache 传输等 intra-node 操作。
尽管 RoCE 在成本上具有一定优势,但其延迟和扩展性仍不能完全满足大规模 AI 系统的需求。为此,论文提出了以下几点改进建议:
- 专用低延迟 RoCE 交换机
- 当前以太网交换机包含大量不必要的功能(如 QoS、VLAN 等),增加了处理延迟。
- 建议开发专门面向 RDMA 工作负载的 RoCE 交换机,去除冗余功能,提升性能。
- 示例:Slingshot 架构已证明基于以太网的设计可以实现接近 IB 的延迟表现。
- AI 转发头(AIFH)与低延迟以太网交换机
- Broadcom 最新推出的 AI Forwarding Header(AIFH)协议可支持更高效的路由机制。
- 结合即将发布的低延迟以太网交换机,有望实现媲美 IB 的性能。
- 这些技术为未来构建高性价比的 AI 集群提供了新路径。
- 拥塞控制算法优化
- 当前 RoCE 使用的拥塞控制机制不够智能,容易导致 Head-of-Line Blocking。
- 建议采用 endpoint-driven 拥塞控制算法,动态调节注入速率,避免严重拥塞。
在 MoE 架构或 All-to-All 通信中,常常涉及大量小数据包传输, 如果由 CPU 处理这些通信任务,CPU 很容易成为瓶颈。特别是在高并发场景下,CPU 的串行处理能力无法满足需求。
InfiniBand GPUDirect Async(IBGDA) 是 NVIDIA 提出的一项用于加速 GPU 与网络设备之间通信的技术。它通过绕过 CPU 的直接参与,使 GPU 能够异步地启动和管理 RDMA操作,从而显著降低通信延迟并提升整体系统吞吐。
- GPU 直接填充 Work Request
- 允许 GPU 直接向 NIC 的队列对(Queue Pair, QP)写入 Work Request(WR)。
- 绕过了传统流程中的 CPU 代理线程,减少上下文切换和同步开销。
- 异步 Doorbell 写入
- GPU 可以直接写入 NIC 的 Doorbell 寄存器地址空间,无需等待 CPU。
- 使用内存映射 I/O(MMIO)方式实现低延迟触发。
- 零拷贝 RDMA 通信
- 数据可以直接从 GPU 显存通过 IB 网络传输到远程节点的 GPU 显存,无需中间 CPU 或系统内存拷贝。
- 特别适用于 EP(Expert Parallelism)中的 All-to-All 通信。
许多研究(包括 DeepSeek 团队开发的 DeepEP )都采用了 IBGDA 技术,并取得了显著的性能提升。
6. 讨论与对未来硬件架构设计的洞见
本章节基于 DeepSeek-V3 的实践经验,系统性地总结了当前硬件架构在大规模 AI 工作负载下的局限性,并提出了面向未来的创新方向。主要围绕以下几个方面展开:
- 硬件限制的实际影响
- 关键挑战与瓶颈分析
- 面向未来的硬件优化建议
6.1 Robustness(鲁棒性)挑战
- 互连失败(Interconnect Failures)
- 当前高性能互连协议(如 InfiniBand 和 NVLink)容易出现间歇性断开。
- 在通信密集型任务(如 MoE 中的 EP 专家并行)中,即使是短暂中断也可能导致性能显著下降或训练失败。
- 单点硬件故障(Single Hardware Failures)
- 包括节点崩溃、GPU 故障、ECC 内存错误等。
- 在超大规模部署中,这类故障的概率随系统规模增加而上升,恢复成本高。
- 静默数据损坏(Silent Data Corruption)
- 多比特内存翻转或计算错误可能未被 ECC 检测到。
- 错误在长期任务中传播,最终影响模型质量。
- 目前依赖应用层启发式策略进行检测,无法保证整体系统的可靠性。
建议改进措施:
- 增强的错误检测机制
- 硬件应引入比传统 ECC 更先进的错误检测机制:
- 如 基于校验和的验证 (checksum-based validation)
- 或 硬件加速冗余检查 (hardware-accelerated redundancy checks)
- 硬件应引入比传统 ECC 更先进的错误检测机制:
- 提供完整的诊断工具包
- 硬件厂商应为终端用户提供全面的诊断工具,帮助用户验证系统完整性。
- 这些工具应作为标准硬件套件的一部分,支持持续监控和预防性修复。
- 提升系统可信度
- 通过嵌入式的诊断和验证机制,增强整个生命周期内的系统透明性和可信性。
6.2 CPU 性能瓶颈与互连优化
尽管 GPU 是深度学习的主要计算单元,但 CPU 在协调计算、管理 I/O 和维持吞吐方面仍不可替代。然而,当前架构存在多个瓶颈:
- PCIe 接口带宽不足
- PCIe 成为 CPU 与 GPU 之间的主要通信接口,但在大规模参数、梯度或 KV Cache 传输时成为瓶颈。
- 例如,饱和 160 条 PCIe 5.0 通道需要超过 640 GB/s 的带宽,对内存带宽提出高达 1 TB/s per node 的需求。
- 内存带宽限制
- 当前 DRAM 架构难以满足如此高的带宽要求。
- 延迟敏感任务的性能瓶颈
- 内核启动、网络处理等任务对单核 CPU 性能要求高,通常需要基础频率高于 4 GHz 。
- 每个 GPU 需要足够多的 CPU 核心来避免控制路径上的瓶颈。
- 对于 chiplet 架构,还需要额外核心支持缓存感知的任务划分与隔离。
6.3 Toward Intelligent Networks for AI
为应对 AI 训练与推理中对低延迟和高吞吐的严苛要求,未来的网络架构应具备的五大关键能力:
- 低延迟通信
- 自适应流量调度
- 高效的拥塞控制
- 强鲁棒性和容错机制
- 灵活的带宽分配与优先级管理
6.3.1 Co-Packaged Optics(共封装光学技术)
在超大规模分布式系统中,传统电气接口的带宽密度和能效已接近极限,引入 硅光子(Silicon Photonics)技术 ,将光学连接直接集成到芯片封装中,可以获得:
- 更高的带宽密度(Bandwidth Density)
- 更低的功耗(Energy Efficiency)
6.3.2 Lossless Network(无损网络)
AI工作负载(尤其是 MoE 中的 All-to-All 操作)对丢包极为敏感,即使是极小的丢包率也可能导致性能显著下降,可以使用 Credit-Based Flow Control (CBFC) 实现无丢包传输,CBFC 原理是通过接收端发放信用额度(credit),发送端只有在获得信用后才可发送数据。但会存在以下问题:
- 如果仅依赖 CBFC,容易引发严重的 Head-of-Line Blocking(HOLB) ,影响整体吞吐。
- 在多路径通信中,单一路径上的阻塞可能导致整个流被卡住
通过引入 Endpoint-driven Congestion Control,如 RTT-based CC(RTTCC)或 Programmed Congestion Control(PCC),能够主动调节注入速率,避免极端拥塞场景。
6.3.3 Adaptive Routing(自适应路由)
传统的 ECMP(Equal-Cost Multi-Path)路由策略无法有效处理 AI 工作负载中高度集中且缺乏随机性的通信模式(如 Data Parallelism 的 AllReduce 或 MoE 的 All-to-All)。自适应路由方法:
- 动态选择最优路径,避免热点瓶颈。
- 提升网络利用率,减少通信延迟。
通过这种方式,可以显著缓解 All-to-All 和 Reduce-Scatter 类操作中的热点问题,提高集群整体通信效率和稳定性
6.3.4 Efficient Fault-Tolerant Protocols(高效容错协议)
大规模训练过程中,网络链路中断、硬件故障等异常情况难以避免。若不能快速恢复,可能造成训练中断、模型损坏等问题。可以引入以下方法解决:
- Self-healing Protocols(自愈协议) :自动检测并修复断开连接。
- Redundant Ports(冗余端口) :提供多条路径,防止单点故障。
- Rapid Failover Techniques(快速切换机制) :如链路层重试机制、Selective Retransmission(选择性重传)
6.3.5 Dynamic Resource Management(动态资源管理)
AI 系统中常常存在混合工作负载(如同时进行训练与推理),不同任务对带宽、延迟、优先级的需求差异大。优化方向:
- 动态带宽分配 :根据任务类型(如 EP、TP、KV Cache 传输)动态调整可用带宽。
- 流量优先级管理 :区分推理任务与训练任务,在统一集群中保证推理任务的响应速度。
| 方向 | 关键技术 | 优点 |
| Co-Packaged Optics | 硅光子集成 | 提升带宽密度与能效 |
| Lossless Network | CBFC + Endpoint-driven CC | 避免丢包,防止 HOLB(Head-of-Line Blocking) |
| Adaptive Routing | Packet Spraying / Congestion-aware Routing | 缓解热点,提升负载均衡 |
| Fault-Tolerant Protocols | 自愈机制 / 冗余端口 / 快速切换 | 提升系统鲁棒性 |
| Dynamic Resource Management | 动态带宽分配 / 流量优先级控制 | 优化混合工作负载表现 |
6.4 内存语义通信与顺序问题(Memory-Semantic Communication and Ordering Issue)
使用 load/store 模型进行节点间通信虽然高效且易于编程,但当前实现受限于内存顺序问题:
- 发送方写入数据后必须显式发出内存屏障(fence),然后才能更新标志通知接收方。
- 这种严格顺序性引入了额外的往返时间(RTT)延迟,并可能导致线程阻塞,影响吞吐量。
此外,在消息语义 RDMA 中也存在类似问题,例如:
- 在 InfiniBand 或 NVIDIA BlueField-3 上执行 regular RDMA writes 后进行 packet spraying 的 RDMA 原子操作,也可能导致乱序同步问题。
建议
- 提供硬件级顺序保障机制
- 硬件应原生支持 memory-semantic 通信的顺序一致性。
- 编程层应通过 acquire/release 语义确保一致性。
- 接收端应由硬件保证数据有序交付,避免额外开销。
- Region Acquire/Release (RAR) 机制
- 接收端硬件维护一个 bitmap,跟踪 RNR(Receiver Not Ready)内存区域的状态。
- acquire/release 操作作用于 RAR 地址范围内。
- 优点:
- 极低 bitmap 开销;
- 实现高效的硬件强制排序;
- 消除发送端显式的 fence 操作;
- 支持 memory-semantic 和 message-semantic RDMA 操作。
6.5 网络内计算与压缩(In-Network Computation and Compression)
MoE 包含两个 All-to-All 阶段:
(1)Dispatch 阶段(路由)
- 类似小规模多播(multicast)操作。
- 单个 token 需要被转发到多个专家节点。
- 建议:硬件应支持自动包复制与多目标转发,大幅减少通信开销。
(2)Combine 阶段(聚合)
- 类似小规模归约(reduce)操作。
- 多个专家输出结果需聚合回原始节点。
- 当前挑战:EP 的归约范围较小且负载不均衡,难以灵活实现网络内聚合。
LogFMT 是 DeepSeek-V3 中用于降低通信量的新型对数量化格式。
- 可以将其原生集成进网络硬件,可以进一步提高熵密度,降低带宽需求。
- 另外,开发硬件加速的 LogFMT 压缩与解压单元,实现无缝集成于分布式系统,提升整体吞吐。
6.6 以内存为中心的创新(Memory-Centric Innovations)
随着模型参数规模呈指数增长,传统高带宽内存(如 HBM)的发展速度远远跟不上需求。
- DRAM 堆叠加速器(DRAM-Stacked Accelerators)
- 利用先进的 3D 堆叠技术,将 DRAM 垂直集成在逻辑芯片之上。
- 优点:
- 极高的内存带宽;
- 超低延迟;
- 实用的内存容量(受堆叠层数限制)。
- 应用场景:
- 特别适用于 MoE 推理中内存吞吐是瓶颈的场景。
- 示例架构:
- 如 SeDRAM,为内存密集型任务提供前所未有的性能提升。
- 晶圆级系统(System-on-Wafer, SoW)
- 使用 wafer-scale 集成技术,最大化计算密度与内存带宽。
- 优点:
- 支持超大规模模型部署;
- 显著提升片上通信效率;
- 应用场景:
- 特别适合处理万亿参数级别的模型。
7. 总结
DeepSeek-V3 是硬件与软件协同设计在大规模 AI 系统中取得突破的典范。通过深入分析当前硬件架构的局限性,并提出一系列切实可行的优化建议,该研究为下一代面向大模型的硬件设计提供了清晰的发展蓝图。
该论文不仅是 DeepSeek-V3 的技术总结,也为未来 AI 硬件架构的发展提供了宝贵的实践指导。随着 AI 工作负载的持续增长,这种“模型 + 硬件”的软硬件协同优化设计诶将成为构建高效、可持续 AI 系统的关键路径。
其核心经验主要包括:
未来硬件设计方向(如统一网络接口、专用协处理器)推动下一代 AI 系统发展。
模型架构创新(如 MLA、MoE、MTP)提升效率。
网络拓扑优化(如 MPFT)降低成本并提升扩展性。
低精度计算与通信优化(如 FP8、压缩、offload)降低带宽需求。
发表回复