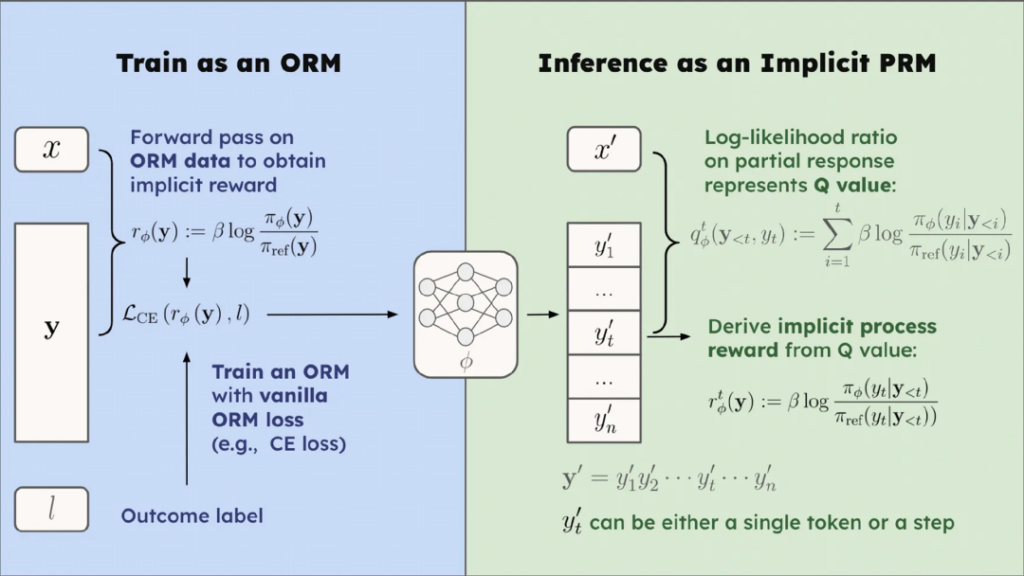
近日,清华大学 NLP 实验室联合上海 AI Lab,清华大学电子系及 OpenBMB 社区提出一种新的结合过程奖励的强化学习方法—— PRIME(Process Reinforcement through IMplicit REwards),采用 PRIME 方法,研究人员不依赖任何蒸馏数据和模仿学习,仅用 8 张 A100,花费一万块钱左右,不到 10 天时间,就能高效训练出一个数学能力超过 GPT-4o、Llama-3.1-70B 的 7B 模型 Eurus-2-7B-PRIME。
具体而言,研究人员利用 Qwen2.5-Math-7B-Base 作为基座模型,训练出了新模型 Eurus-2-7B-PRIME ,并在美国 IMO 选拔考试 AIME 2024 上的准确率达到 26.7%,大幅超越 GPT-4o,Llama3.1-70B 和 Qwen2.5-Math-7B-Instruct,且仅使用了 Qwen Math 数据的 1/10。其中,强化学习方法 PRIME 为模型带来了 16.7% 的绝对提升,远超已知的任何开源方案。
https://www.infoq.cn/article/9WdYUx1JVh0xZ0GfQcVx


发表回复